

This paper tackles an important point when using spreadsheets as teaching aids, namely how to publish the spreadsheets on the Web.
The paper has been written from our experiences of writing spreadsheet simulations for the Virtual Learning Arcade ( http://www.bized.ac.uk/virtual/vla/ ). The primary focus of this article is the role of the Model Master toolkit used to prepare spreadsheets for publication on the Web.
The student's understanding of economic models is crucial to their understanding of economics. By their very nature spreadsheets lend themselves to assisting an individual's understanding of models through experimentation. The benefits of using spreadsheets as a teaching aid have been well documented. The diversity of applying spreadsheets to teaching economics in Higher Education is evident from the recent articles in CHEER. For instance, Mixon & Tohamy (2001) applied Microsoft Excel for teaching an Introduction to International Trade course, aimed at first year students. In contrast, Cahill and Kosicki (2001) applied spreadsheets to support teaching second and third year students the issues of the neoclassical assumptions within a Keynesian model.
The Virtual Learning Arcade (VLA) provides interactive online models that illustrate and test the fundamental principles of economics. Some of the simulations look at large scale or even global issues, while others focus on distinct topics. The simulations are supplemented with support materials that have been written to further enhance the educational value of the simulations. This includes explanations of the theories associated with the models and simulations, interactive worksheets, glossaries and guidelines.
This paper explores the method by which educators can convert their spreadsheets to be distributed through departmental intranet / internets, and how these online spreadsheets can be further supported to enhance their value as learning objects.
An important issue for educators is the method by which they distribute their spreadsheets. The conventional approach is either allowing students to download the file or allowing access through college networks. Both these approaches have limitations. In particular there is the issue of access and the provision of support material. For instance, the student must have a valid version of the proprietary programme (i.e. Microsoft Excel) on their computer, and spreadsheets - electronic ledgers - are limited in how they display textual information. Both of these problems can be overcome if the spreadsheet can be published on the Web in a format that is browser-independent.
The VLA will publish approximately ten spreadsheet-based models on the Web, all written in Excel. One, typical in its structure and size, is a model of the housing market. We shall use this to illustrate the method of conversion.
Figure 1 illustrates the worksheet. The model is a simple supply and demand equilibrium model, where the demand and supply curves are determined by factors such as, household income, price of complements and substitutes, alternative production possibilities for firms and government regulation. The spreadsheet design allows for the student to change all input parameters, including the elasticity conditions. The model output is in the form of the new equilibrium position and the percentage change from the previous position. It is evident that the spreadsheet would have considerable potential for teaching the microeconomic principles on an introduction to economics course.
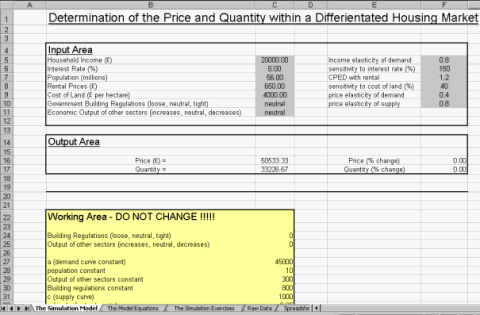
Figure 1: Excel Model of the Housing Market
As most Web users now know, there are two different ways to run Web-based programs: server-side and client-side. Server-side applications run entirely on the Web server. The user sends input via an HTML form, and receives output back from the server as a new Web page. Client-side applications run on the user's browser, usually as Java applets or Javascript programs. They offer more interactivity than server-side. For example, if the user types an invalid number into an input field, a client-side program can respond immediately by popping up an error message. Its server-side equivalent would have to wait until the user presses a "Submit" button, and then could respond only by sending back another Web page. Similarly, if the user wants a graph of some results plotted, a client-side application could do this by popping up the graph in a new window without destroying previous displays, and might then let the user dynamically resize the graph, or click on a point to zoom in on the surrounding area.
This project uses only server-side processing. Although it restricts interaction, it compensates with other advantages. The user does not have to download and install a Java interpreter, often necessary when using applets. The browser's memory requirements are less. And almost any browser can be used, even the text-only browser Lynx, so we reach a much wider audience.
In the next two sections, we give a general introduction to Model Master, and then explain how we published our spreadsheets.
Like cornflakes, vaccination and vulcanised rubber, Model Master (MM) was invented by accident (note1), in this case as a by-product of research into the foundations of object-oriented programming. It started life as a tool for writing spreadsheets in a less error-prone way than by typing them directly into Excel. The idea is that the modeller can write a series of equations which MM will then convert into a spreadsheet. The process is similar to using a conventional compiler, except that instead of turning a program into a .exe file, MM generates a spreadsheet. Instead of inscrutable cell addresses such as C9 and F6, the modeller can write meaningful variable names such as CostOfLand and SensitivityToInterestRate, and can either tell MM which cell to use for each variable, or let it decide for itself. Together with the ability to write comments in the program, and some special features for reusing code from libraries, these make the program easy to read and maintain. Information on MM is available at http://www.j-paine.org/mm_publications.html .
Writing spreadsheets in this way suits modellers accustomed to conventional languages like Fortran, or mathematical toolkits such as Mathematica and Unisolve. However, many people do prefer to program directly in Excel. So as well as the MM compiler, we have implemented a "decompiler" which goes the other way, translating existing spreadsheets into MM programs. Our intention was that modellers, having originally developed their program in Excel, could decompile it into an MM program and from then on use that as the primary source, because of its greater intelligibility and maintainability. However, even if the modeller chooses not to do that, the MM program is also a good concise summary of the spreadsheet's structure and content, and can be useful just as an aid to error-checking. To make these summaries more readable, we have equipped the decompiler with heuristics that enable it to guess sensible names for cells by looking at text labels in adjacent cells. Of course, sometimes these heuristics make a wrong guess, so the modeller can override them. Figure 2 below shows an MM listing of the Housing Market model with the original cell names, and Figure 3 shows one with names chosen according to MM's heuristics.
C5=15000
C6=6
C7=56
C8=650
C9=4000
C10="neutral"
C11="neutral"
C16=((C27+(F5*C5)
-(F6*C6)+(C7*C28)+(C8*F7)+C31+(C25*C29)+(C9*C32)+(C24*C30)
)/(F9+F10)
C17=C27-(F9*C16)+(C5*F5)-(F6*C6)+(C7*C28)+(C8*F7)
C24=IF(C10="neutral",0,IF(C10="loose",-10,10))
C25=IF(C11="neutral",0,IF(C11="decreases",-10,10))
C27=45000
C28=10
C29=400
C30=1000
C31=1000
C32=0.05
F5=0.9
F6=25
F7=1.1
F8=30
F9=0.4
F10=0.8
F11=49020.83
F12=40016.67
F16=((C16-F11)/F11)*100
F17=((C17-F12)/F12)*100
Figure 2: MM-language summary of the Housing Market model
HouseholdIncome=15000
InterestRate=6
Population=56
RentalPrices=650
CostOfLand=4000
BuildingRegulations="neutral"
OutputOfOtherSectors="neutral"
Price=(a+(IncomeElasticityOfDemand*HouseholdIncome)+
(SensitivityToInterestRate*InterestRate)+
(Population*PopulationConstant)+(RentalPrices*CPEDWithRental)+
c+(OutputOfOtherSectorsFactor*OutputOfOtherSectorsConstant)+(CostOfLand*e)+
(BuildingRegulationsFactor*BuildingRegulationsConstant)
)/(PriceElasticityOfDemand+PriceElasticityOfSupply)
Quantity=a+(PriceElasticityOfDemand*Price)+
(HouseholdIncome*IncomeElasticityOfDemand)+
(SensitivityToInterestRate*InterestRate)+(Population*PopulationConstant)+
(RentalPrices*CPEDWithRental)
BuildingRegulationsFactor=IF(BuildingRegulations="neutral",0,
IF(BuildingRegulations="loose",-10,10))
OutputOfOtherSectorsFactor=IF(OutputOfOtherSectors="neutral",0,
IF(OutputOfOtherSectors="decreases",-10,10))
a=45000
PopulationConstant=10
OutputOfOtherSectorsConstant=400
BuildingRegulationsConstant =1000
c=1000
e=0.05
IncomeElasticityOfDemand=0.9
SensitivityToInterestRate=25
CPEDWithRental=1.1
SensitivityToCostOfLand=30
PriceElasticityOfDemand=0.4
PriceElasticityOfSupply=0.8
OriginalPrice=49020.83
OriginalQuantity=40016.67
PriceChange=((Price-OriginalPrice)/OriginalPrice)*100
QuantityChange=((Quantity+OriginalQuantity)/OriginalQuantity)*100
Figure 3: MM-language summary of the Housing Market model, after renaming cells
MM also provides facilities for error-checking spreadsheets. For example, it can detect constants and input cells that are never referenced in other formulae, and output cells which are never changed by anything in the spreadsheet. This and the listings generated by the decompiler have already proven useful in helping us detect errors in our models.
Finally, we have also developed a spreadsheet evaluator for MM. This takes a spreadsheet and a list of values for its input cells, and evaluates all the formulae, giving a list of values for the output cells. The evaluator is written in Java, and can be called from any Java-capable Web server. This is what we are using to run our Web-based models.
We shall demonstrate the use of MM. In this section, to make it clearer who is doing what, we write our description as instructions, addressing the modeller as "you".
The first step is to save the spreadsheets as a SYLK file. Then you need to make the Web pages. This raises the question of how users interact with the model. Generally speaking, the original spreadsheet will have its inputs and outputs simultaneously visible within the same worksheet. We could imitate that, so that the entire model is presented on one Web page which contains both the input fields and the outputs. However, we decided for reasons of consistency with other learning objects within the VLA to have inputs on one page and outputs on another. Amongst other things, these will contain links to the support materials.
The starting point is to write both pages as normal HTML files, leaving spaces where the inputs and outputs will eventually go. This can be anywhere - in tables, in lists, in headings, in the middle of a paragraph. Tables are convenient, because they make it easy to place short labels. However, there is no need at all to follow the layout of the original spreadsheet, nor is it even necessary to put all the cells in the same table. The spreadsheet is being used merely to run the model, not to display it. The input page does need to have all inputs enclosed within a form, which must have a "Submit" button.
Once you think the pages are ready, check them in a browser. The next stage is to add the model's inputs and outputs. To simplify doing this, we have written a tool called WSM (note2) which makes it easy to write menus and to associate cells with locations on the pages. Start with the input page. It now needs to be renamed so that it has the extension .pfn. You also need to: prepend the magic symbols (args) ] as a header before anything else in the page; to change the form definition so that it looks like <FORM ACTION=[ (wsm-action 'run) ]>; to add a hidden field <INPUT TYPE=HIDDEN NAME=filename VALUE="house_prices.slk"> giving the name of the spreadsheet SYLK file; and to add another hidden field <INPUT TYPE=HIDDEN NAME=out VALUE="HousePricesOut"> giving the name of your output page. It will have been necessary, when installing MM and WSM, to configure them so that they know the directories in which the pages and SYLK files are stored.
Having thus prepared the input page, specify each input field. Actually, we use menus rather than fields, to avoid the need for error-checking. Menus are specified by giving the name of the cell and the menu's contents: [ (menu "C7" "55 to 60" 56) ] or [ (menu "C5" "15000 to 25000 by 1000" 20000) ]. Inside the square brackets, the first string is the name of a cell. The second specifies a list of values to appear in the input menu, and the third is the default. The values can be written in the form of a loop, to simplify generating long sequences of repetitively changing prices, rates, or other quantities. Figure 4 shows an extract from the Housing Market model's input page.
(args)
]
<html>
<head>
<title>Virtual Learning Arcade - Modelling House Prices</title>
</head>
<body>
<h2>Modelling House Prices</h2>
<h3>The Inputs</h3>
<hr width="350" align="left">
<form method=get action=[ (wsm-action 'run) ]>
<input type=hidden name=filename value="house_prices.slk">
<input type=hidden name=out value="HousePricesOut">
<table border="1" cellspacing="2" cellpadding="5" bgcolor="#6699cc" width="450">
<tr>
<td colspan=2><h3>Demand & Supply Conditions</h3></td>
</tr>
<tr>
<td bgcolor="#99bbdd">Household Income (�)</td>
<Td bgcolor="#99bbdd">[ (menu "C5" "15000 to 25000 by 1000" 20000) ]</td>
</tr>
<tr>
<td bgcolor="#99bbdd">Interest Rate (%)</td>
<td bgcolor="#99bbdd">[ (menu "C6" "2 to 10" 6) ]</td>
</tr>
<tr>
<td bgcolor="#99bbdd">Population (millions)</td>
<td bgcolor="#99bbdd">[ (menu "C7" "55 to 60" 56) ]</td>
</tr>
... etc ...
</table>
</form>
... etc ...
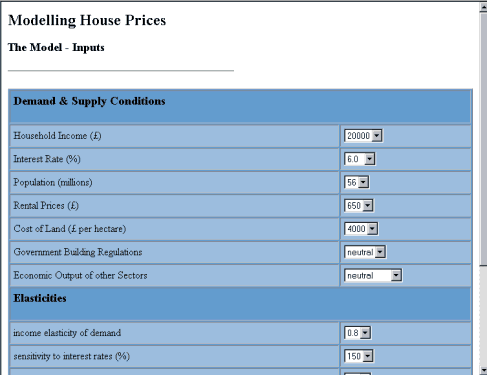
Figure 4: Input page
Preparing the output page is similar, except that: the header is (args this-page program valuemap) ]. There is no need to worry about forms, menus, or hidden fields; and the outputs are specified as in [(output valuemap 'C5)].
(args this-page program valuemap)
<html>
<head>
<title>Virtual Learning Arcade - Modelling House Prices</title>
</head>
<body>
<h2>Modelling House Prices</h2>
<h3>The Model - Outputs</h3>
<hr width="350" align="left">
<table border="1" cellspacing="2" cellpadding="5" bgcolor="#6699cc" width="450">
<tr>
<td colspan=2><h3>The Input Conditions</h3></td>
</tr>
<tr>
<td bgcolor="#99bbdd">Household Income (�) = </td>
<td bgcolor="#99bbdd">[(output valuemap 'C5)]</td>
</tr>
<tr>
<td bgcolor="#99bbdd">Interest Rate (%) = </td>
<td bgcolor="#99bbdd">[(output valuemap 'C6)]</td>
</tr>
<tr>
<td bgcolor="#99bbdd">Population (millions) =</td>
<td bgcolor="#99bbdd">[(output valuemap 'C7)]</td>
</tr>
... etc ...
</table >
... etc ...
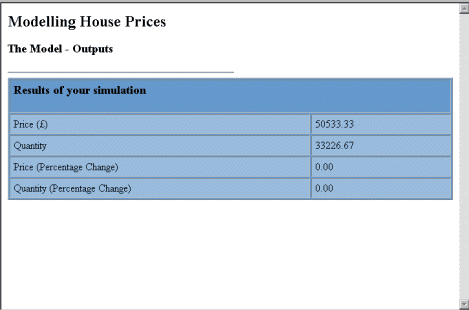
Figure 5: Output page
Once one model has been done, it is easy to copy parts from one Web page to the next, so pages can be prepared extremely quickly. For models as simple as the Housing Market one, we need only an hour or two per page, most of it spent in designing the layout. One possible source of problems is getting the cell names in the pages wrong. To help diagnose this, you can insert commands into a page to display the entire spreadsheet in its grid as a table, making it easy to compare its cells with the inputs and outputs.
The VLA has the working version of this simulation with the supporting material (http://www.bized.ac.uk/virtual/vla/house_prices/index.htm).
Although we have published most of our models as described above, there are other ways in which MM can be used.
For Java programmers who prefer to write their own servlets rather than relying on WSM and its templates, we have provided a Java interface to MM's evaluator. There are methods for loading a spreadsheet file, storing values in its input cells, running the spreadsheet, and extracting the new values calculated by the evaluator from its output cells. Typically, the servlet author would write the input page in HTML, including in it an input form containing fields or menus. The server would be configured so that when this form is submitted, the inputs are passed to the servlet. This must call the Java interface to load the spreadsheet, pass it the input values, evaluate it, get the outputs, and construct an output page with them embedded in it. An example is BrumCars within the Virtual Learning Arcade ( http://www.bized.ac.uk/virtual/vla/ ).
The MM Autopublisher is a prototype of a service which will automatically publish a spreadsheet on the Web. It generates model input and output pages similar to those shown above, using the tools developed for the work described in Section 4, but does not require the user to write in HTML or to do any Web administration. All that is necessary is for the user to submit a SYLK file to our server via a form. The server passes it to MM, which analyses it, generates HTML code for the input and output tables, and embeds this in Web pages which it then copies to a public directory for anybody to use.
To control layout, the modeller must put special commands in the spreadsheet itself. For example, to indicate that cells C5 to C17 are to be included in the input table, the modeller writes the word input in column A followed by the label C5:C17 in column B. To set a menu for cell C5, the modeller writes the word menu in column A followed by the text C5 in column B, and (for example) the text 15000 to 25000 by 1000 in column C. This is based on the premise that while modellers may not feel comfortable with HTML or server configuration, they certainly will be accustomed to typing simple control commands into a spreadsheet. More information about the Autopublisher is available at http://www.j-paine.org/mm_autopublisher.html .
There are several ways that MM could be developed for the spreadsheet-teaching community.
This paper has outlined how an Excel spreadsheet model can be converted and published on the Web using the Model Master Toolkit. The Model Master Toolkit is a highly versatile package that allows spreadsheets to be written, edited, run and published on the Web.
1. The idea for MM arose from some work in General Systems Theory on the nature of objects and systems, and its application to what we call System Limit Programming. This turned out to apply to a wide range of phenomena, constraint-based programming languages amongst them, and spreadsheets amongst these. It soon became evident that we could easily design a language which could compile into spreadsheets, and that this would increase the safety and maintainability of spreadsheet programming. The MM compiler is implemented in a reasonably normal fashion, except that storage allocation is for a two-dimensional memory where the positioning of variables is important. The decompiler works in the other direction, but differs from the compiler in that it needs interactive guidance. Heuristics, such as the name-guessing rules above, must always be overridable; using the decompiler is more like using an interactive algebra manipulation for manipulating spreadsheets than it is like running a straight-through program. The evaluator performs a dependency analysis on the spreadsheet and then evaluates the expressions in the cells in dependency order. The routines used, particularly in the evaluator and decompiler, are also useful in error-checking.
2. WSM is a tool broadly similar to Active Server Pages or Java Server Pages, which makes it possible to embed dynamically evaluated expressions in Web pages. WSM is implemented in the Kawa programming language, a version of Scheme, and compiles .pfn files into Kawa functions whose output is a string making up the page to be displayed and whose input is a list of arguments which may include some global state. The magic symbols in the header specify the function's argument list, and square brackets are used to enclose expressions. Everything else is assumed to be verbatim text. The syntax of WSM was inspired by Bruce Lewis's Beautiful Report Language, although the implementation is original. To make it easy to write session-based applications with global state, WSM comes with a servlet that implements a state-transition machine. To implement a new application, it is necessary only to provide WSM with a specification of its transition network. When installing MM, we also installed WSM, and wrote a transition network that implements the running of any spreadsheet model, needing only to be supplied with the location of the model and its output page. These are the parameters passed in the two hidden fields. The form's action URL tells WSM that the transition network is to receive the action run, i.e. run the model. WSM is described more fully in http://www.j-paine.org/wsm.html .
Mixon, J. W. and Tohamy S. (2001) "Using Microsoft Excel in Principles of Economics". CHEER Volume 14 Issue 2 pp 4-6.
Cahil, M.B. and Kosicki, G. (2001) "Using Spreadsheets to Explore Neoclassical Assumptions in a Keynesian Model" CHEER Volume 14 Issue 2 pp 7-11.
Jocelyn Paine
Visiting Fellow
ILRT
University of Bristol
UK
popx@j-paine.org
http://www.j-paine.org/
Tel: +44 (0)7768 534 091
Andrew Ramsden
Research Officer
ILRT
University of Bristol
UK
andy.ramsden@bristol.ac.uk
http://www.bized.ac.uk/
Tel: +44 (0)117 928 7124