

The CTI Centres, along with all the 20 or so other CTI Centres were charged earlier this year with setting up either a World Wide Web or Gopher server. By far the majority of Centres have chosen to make available WWW servers to their constituencies. The overwhelming reason for this is almost certainly the unique flexibility provided by the WWW to enable users to transfer text, image (still and video) and sound files in a variety of user friendly ways.
This paper is aimed primarily at the Internet/World Wide Web novice who wishes to understand better how the WWW works and would like to know how to create HTML files, either to enhance their own information searching effectiveness or as a means of becoming an effective information provider on the Web. It describes the tools currently available for distribution or personal use. The paper briefly introduces the World Wide Web client/server architecture and discusses in more detail the Hypertext Markup Language (HTML) used to produce source documents and the linkages that constitute the Net. Sufficient additional reference material is provided to enable the reader to collate all necessary data in order rapidly to become proficient in the creation of HTML documents.
No self respecting discipline is without its quota of jargon - computing is no exception - and the Internet is replete with buzz words. Here are some of the more important from our perspective.
There are specific WWW Server programs that are available. These are well documented on the Web either from NCSA or CERN and beyond the scope of this paper. The Client architecture is rather different. There are several ways in which users can access the Web. Typically this would be via either a text client such as Lynx (this enables text information held on the Web to be accessed using VT100 terminals and while useful misses out on the graphical power of the Web) or a graphical client such as Cello or the NCSA Mosaic. Both of these graphical browsers are available via the Internet as freeware (downlaod using PC/NFS) for system X, MS Windows and Macintosh. They provide access to graphical information as well as the ability to display text in a configurable format (fonts, styles and sizes). Figure 1 shows a typical MS Windows Mosaic interface.
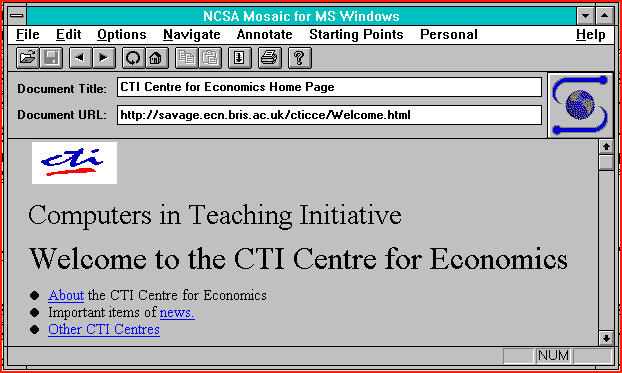
Figure 1
At the CTI Centre for Economics we extensively use the MS Windows version of the NCSA Mosaic client software. The version shown in figure 1 is the 2.0 Alpha 2a 16 bit MS Windows version. You should be aware that this software is still very much under development. There is also a 32 bit version available for those with suitable hardware.
The other browser, CELLO, has a much simpler interface - see figure 2.

Figure 2
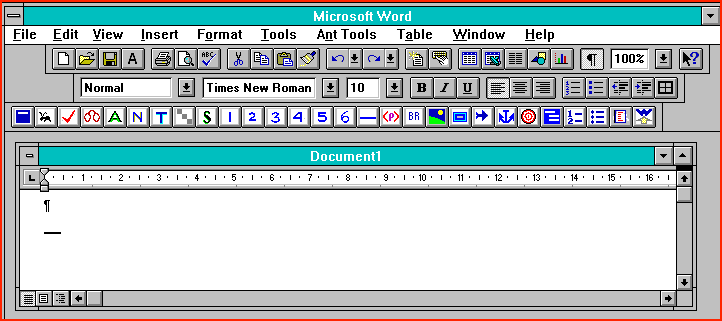
There are a number of authoring tools available for use with MS Windows and as add on templates for wordprocessing packages (Word for Windows Version 2.0 and 6.0) to aid the creation of HTML documents. We shall take a look at two of these. First, we will briefly consider ANT_HTML.DOT, a template add in for MS Word for Windows 6.0. For those who have access to Winword 6.0 this template is well worth acquiring. Again it is currently available as freeware. Further details can be obtained from the author:
Jill Swift jswift@freenet.fsu.edu.When implemented it looks as shown in figure 3.

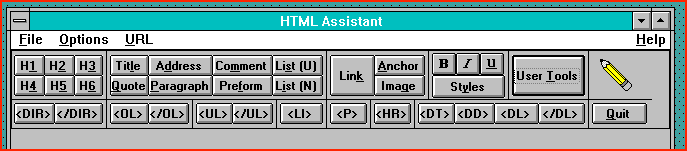


We will outline the use of HTML Assistant to create some simple documents with URL links to other servers and describe the function and use of Tags. You can see from the HTML Assistant Inteface in figure 8 that much of the tagging can apparently be done at the click of the mouse button. This is true but we do need to conform to a number of conventions.

The new paragraph indicator < P > is an exception under current HTML conventions and is acceptable under HTML+ conventions. The <TITLE> tag indicates the title of the document and will be displayed by the browser in the title box at the head of the document. The tag < H1 > defines the first level of header, and the browsers will display up to six levels of headers. The <EM> tags are used to emphasise text.
While this represents the bare bones of an HTML document and might be
correctly interpreted by most browsers, there are some additional tags
which need to be added to ensure that the document is interpreted
correctly 100% of the time. These are <HTML>, <HEAD> and
<BODY>. They ensure that the spiders (or robots) used for indexing and
auditing function correctly and efficiently and hence that the document is
correctly interpreted to the client browser. Figure 10 shows that by
adding these tags and including a link to a server a simple but complete
HTML document results.

One curiosity of HTML Assistant Version 1.0 is that (unlike version 1.3 Beta) it does not include tags for ,
or . You do have the facility to add these to the "User Tools" button as custom tools if it is your intention to create full HTML documents for use on a server.Mike Emslie
CTI Centre for Economics, University of Bristol
Notes: (i) This is a shortened and edited version of a paper presented at the CALECO conference at Portsmouth in September 1994. (ii) As from this issue of CHEER the full text and graphics content of CHEER will be mounted on the Bristol server for access via the Web using NCSA Mosaic or similar client software.