

Be Your Own Chancellor was reviewed by Mike Emslie in the November 1995 CHEER, and is available on the Web via the IFS home page. If you try it, you'll see that it involves a simple "one-shot" style of interaction. You pull up a Web form, select menu options to set tax rates and other parameters, submit the form, and then wait for a page to come back with the results. But simplicity notwithstanding, BYOC is an effective way of helping people understand the British tax system. The Web's hypertext nature adds extra value, because input forms can be linked to help-text. This explains terms such as SERPS and MIRAS that some may find unfamiliar, as well as general information on matters like personal tax allowances and the limitations of the model.
BYOC is based on Taxben (Giles and McCrae 1995), an "industrial strength" microsimulation model developed by the IFS as a research tool for assessing the distributional effects of changes to the tax and benefit system. Although the IFS use and modify Taxben frequently, it was conceived long before Tim-Berners Lee invented the Web, and still does its input and output as it did originally, from files. So how did we connect the two? You might have your own teaching programs that you'd like to put on the Web, and in this article, I shall explain how.
Please note that this article will not turn you into a Web expert. The Web was not designed for running programs in this way, and anyone who gets involved with implementation will need to master subtleties that bring to mind Jackson Granholme's definition - "An ill-assorted collection of poorly matching parts, forming a distressing whole" - for the word "kludge" (Raymond 1996). It can be done, but it feels shaky, and the wonder is that it works at all. So I do recommend enlisting the help of a friendly Web expert.
But that should not discourage you. Though it can be difficult to put up large session-type applications without special software, the good news is that "one-shot" programs like BYOC can, with the aid of a knowledgeable programmer, be connected quite simply. It took us two hours to connect our first program, starting from a point where I had never seen the IFS Web server before. Furthermore, once the first application has been connected, most of the work will be reuseable. There are too few educational programs on the Web: my objective is to show that you too can turn your existing programs into high-quality distance-learning applications.
Suppose that you ask your Web browser to go to a particular URL, for example the IFS home page at http://www.ifs.org.uk/index.htm .
Now, the URL contains a site identifier and a page identifier: www.ifs.org.uk and /index.htm respectively. The browser extracts them and constructs an "HTTP request line" which looks like this:
GET /index.htm HTTP/1.0It then tells its machine's Internet software to send this to the named site. If that machine's own Internet software is working correctly, it will interpret the request as a Web transaction, and pass it to its Web server, which therefore receives the line shown above. The first word in this line states what type of request it is. There are several types: for example PUT asks the server to add a new Web page, while HEAD asks for information about a n existing page. But for our purposes, the important ones are GET and POST.
GET requests a page, and may, as we'll see in the next section, also carry data sent from a form.
POST is a variant of GET used only with forms, which sends its data in a slightly different way.
The names of these request types, and the syntax of the request, make up a small language or "protocol" that the browser and server must jointly understand. As ever in computing, there are different versions of this: the third word in the line, HTTP/1.0, tells the server which one the browser is using.
The business end of the request is the second word, /index.htm, which names the Web page the user wants. Handling this is simple. On most systems, pages are stored as text files under a particular root directory. This means that the server just needs to add the name of this directory to find where the page lives. So if, as at the IFS, the directory is /pub/html, then the file would be /pub/html/index.htm. The server can then send this back.
Enter tax rate:<INPUT TYPE=TEXT NAME=rate><BR> Enter tax threshold:<INPUT TYPE=TEXT NAME=thresh><BR>then the data might look like this
rate=20&thresh=4100That is not all. Because an application could have more than one form, the server must also have some way to tell which is which. That is provided by the "action URL", a form identifier that you write as part of the <FORM> tag that starts every form definition. When you submit the form, the browser glues this action URL onto the start of the data, separated by a question mark. There are other details - for example, dealing with POST commands, and knowing how spaces and other special characters get encoded - but these are essentially simple and can be found in good Web guides. Here, the important point is that the data arrives at the server in an easy-to-handle format, and that the server can always tell, if you have several forms, which one the data came from.
So let us assume that the form above had byoc as its action URL. Then the server would receive the string
GET /byoc?rate=20&thresh=4100 HTTP/1.0We have now jumped the first hurdle, that of understanding how data gets from the browser to the server. Next, how do we make the server run a program which can process this data?
If the server does decide to run a program, how can it pass the data to it? Recall that this arrives as a string of name-value pairs, rate=20&thresh=4100.Your program will already expect to read its data from an input file in some particular format. So you could program your server to take the data string and write it into a temporary file, reformatting it into whatever format the program prefers. The server can then issue a system command to start the program with this file as input. The advantage of this is that it involves minimal disturbance to existing code.
Actually, at the IFS, we did a bit more. We made our server write the data to a temporary parameter file, one name-value pair per line:
rate 20 thresh 4100We also wrote some input routines which would search such a file for a specified name (e.g. rate) and return the corresponding value (e.g. 20). We had to rewrite existing programs to make them call these routines, but that was a small change, and we then had a general way of transferring input from any Web form to any program. We have since extended the range of formats these parameter files can contain, and we now use them as a general means of passing tax systems and other data between programs.
Incidentally, forms can contain "hidden fields", which send their data in the same way as normal date-entry fields, but which are not visible to the user. These can be used to store extra data in a form. One way to use them is to have them carry the form's identification, rather then putting it in the action URL. Another is if the form was generated automatically in response to an earlier query. In that case, hidden fields can be used to convey data from the earlier query, as we see later.
I assume above that your server script gets handed the raw HTTP request line and then does the rest of the processing itself. Not all servers work this way. Some have a hidden script which you never see, whose processing is driven by configuration files that you can modify. They may let you specify, for example, that any page request whose name starts with /programs/ is to run a program of the same name. In this case, it may still be best to have the server call a script that then invokes your program, rather than running the program directly. This will give you more control over the data reaching it.
In either case, there are some places where you must take care. For example, if your server creates temporary program input files, they will eventually need to be deleted to prevent your disc overflowing. Remember that two HTTP requests may arrive simultaneously, so you must avoid conflicts by giving each file a unique name. Make the server check its input carefully so that it always sends back a suitable error message if asked to process a form it doesn't know about or a piece of data in the wrong format. Error checking is important: browsers sometimes send incorrectly formatted requests, and some users will delight in catching you out by trying to do the same. Check also that all the data you expected has actually arrived.
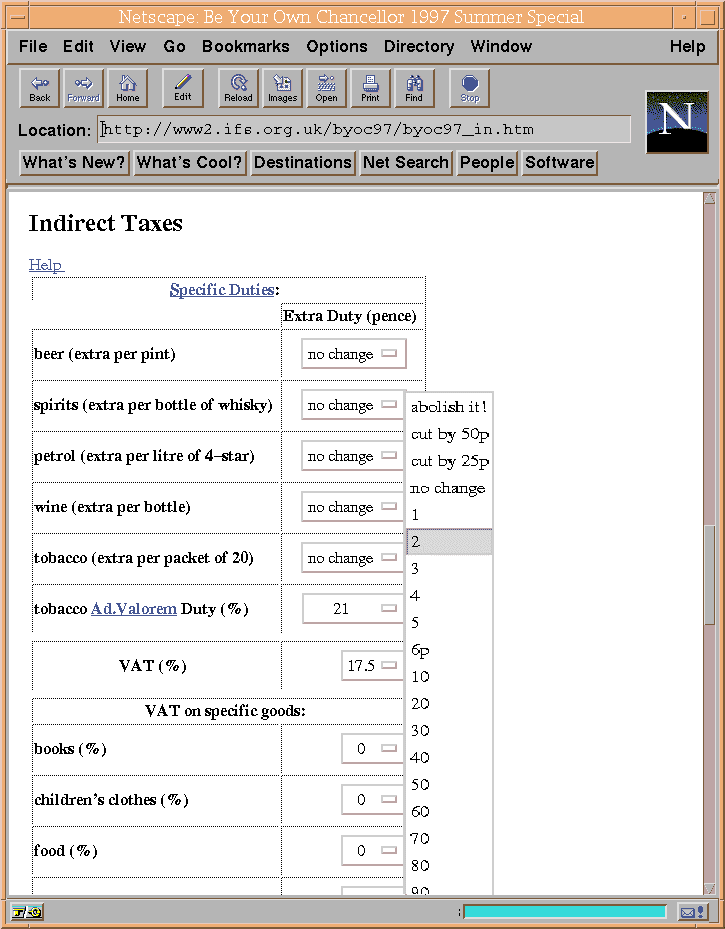
We found that a good way to avoid needing to error-check numeric data was to use menus, thus preventing the user entering numbers that contain illegal characters or are out of range.
If the program only needs to fill a few slots in an otherwise-constant output page, there is another possibility. It could write out a small parameter file, similar to the input files discussed above. Then the server could read this and splice the parameters into their correct places in a page template. This takes more programming, though.
Near the cartoon is an image summarising how much the household gains or loses per week. This is either an upward-pointing blue arrow or a downward-pointing red arrow accompanied by a legend such as Loses �5-�9 or Gains �2-�4. You might think these images are being generated dynamically. In fact though, things are simpler. We have a selection of different-sized arrows, held in files with names like loses_upto_9.gif and gains_upto_4.gif. BYOC just rounds the household's net gain or loss, and then generates a filename from it, thus choosing an arrow size as appropriate.
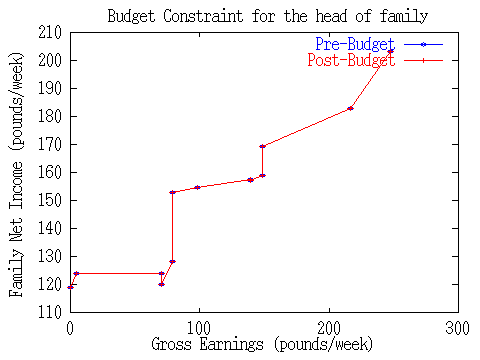
To generate these graphs, BYOC writes a list of coordinates to another temporary output file, different from the one it sends the HTML to. Our server then passes this file to the freeware plotting program Gnuplot, which plots a graph in GIF image format. BYOC inserts another <IMG> tag in its HTML output to refer to this image file. Because HTML itself has no drawing commands, any dynamic plot would have to be created this way.
Incidentally, those teaching labour-supply economics may like to know that BYOC accompanies each graph by a table of kink points. This identifies each kink by its gross and net income coordinates, and also shows the marginal tax rate and a sentence or two explaining what caused the kink. BYOC uses an elegant recursive algorithm for finding these kinks, described in (Duncan and Stark 1994).
<SELECT NAME=TaxRates> <OPTION>0<OPTION>1<OPTION>2<OPTION>3 </SELECT>We made things simpler by writing a preprocessor, MDDL, that took an abbreviated dialect of HTML and translated it into the standard version. One feature of this dialect was its ability to express menus concisely. Instead of the example above, one could write simply <? TaxRates INTEGER OPTIONS="0/1/2/3">. We could also define menus whose options changed by regular increments: the definition OPTIONS="0 to 100 by 20" was expanded in to a menu with options 0,20,40,60,80 and 100.
In general, by using a preprocessor, you can customise an existing notation by making it more concise, readable, or whatever. For example, most C programmers use a preprocessor built in to the C compiler to substitute numeric constants like 10 for symbolic names like newline, thus improving the readability of their programs. In effect, preprocessors allow you to define a "little language" to fit your own needs. Writing a preprocessor is one area where the help of a skilled programmer will definitely be needed, but I mention it because if the effort can be made, there can be great savings in making code easier to read and write.
Your age? <? Age INTEGER SIZE=20>would correspond to the standard HTML
Your age? <INPUT TYPE=TEXT NAME="Age" SIZE=20>and MDDL would translate the one into the other.
Instead, one could write a menu:
Your age? <? Age INTEGER OPTIONS="1/2/3/4 <I>etc</I>">and MDDL would translate it as in the previous section, though because of the number of options needed, this would not be particularly useful!
Why might a program want to to know the user's age? One reason, if it is giving advice on the user's tax situation, would be to check whether the user is above pensionable age or below. So suppose that the program is already set up to read a real age, but that it only differentiates between ages over 60 and those under (we'll ignore the complication that men and women have different retirement ages). All we need to do then, is to make a menu which asks whether you are under 60 and if so, sends back any a ge under 60; otherwise, sends back any age of 60 or more. In MDDL, we can do this by saying
Your age? <? Age INTEGER
OPTIONS="Under 60:58/60 or more:60">
MDDL implements this by writing out a small translation table which the server must consult whenever it receives data from the user. So we have a way to specify translations for menu options, allowing the user to enter a string which is translated
to a number before it hits the program. MDDL also gives us the freedom to write menus using almost the same syntax as text-entry fields, making it easy to convert one to the other. This paragraph is not intended to extol our cleverness in building
MDDL, but once again, to demonstrate the advantages that preprocessors bring.
Finally, we mention that MDDL had a scaling feature. Menu ranges could include a scale directive, which would multiply the selection by a given factor before it was passed to the program. This was useful in writing programs that could accept income as either a monthly or a weekly figure.
Families vary: some have one earner, others two; some own houses and receive Mortgage Interest Relief, others rent their accomodation; some have company cars, others don't. The detailed information needed by Budget 97 depends on such characteristics: there is no point in asking house-owners about rent, or single earners about a spouse's income. If you try the program, you will see that it handles this by using two forms. The first asks a few simple questions - have you a house, are you married - and then sends back another more detailed form.
This is necessary because a Web page can't change without communicating with the server. You cannot click on a "house owner" button and immediately see new fields appear for you to enter details of your mortgage. (As I implied earlier, that is not true if you use Java. There is also a language called JavaScript, implemented by Netscape and some other browser manufacturers, that allows pages to modify themselves by running a program in the browser. JavaScript can be useful, but be warned that it is in its infancy. Current implementations are full of bugs and often not compatible with one another - as we discovered the hard way when we tried using it.)
To get round this, we created a template file for Budget 97's second form, with "conditional flags" in it. These delimited regions of text which were only to be included if a given answer to the first form was true. When the user submitted the first form, the server ran over this template and created a new form by inspecting the flags and inserting chunks of text as dictated by the user's answers. This is a technique worth knowing.
Programmers have been aware of this for several years, and have devised various workarounds. One is for the server to embed data submitted during one transaction in the form that transaction generates, so that when this second form is submitted, the data will again be sent to the server. Budget 97 does this, using hidden fields. Another is for the server to store the data locally, but to embed a unique identification key in the generated form. When the form is submitted, the server retrieves the stored data using this key. If the generated page is not a form, you can't use hidden fields: an alternative is to use a key, but to embed it in the page's URL rather than the page itself. It should now be clear why I devoted most of the article to one-shot applications, in which state need not be preserved.
It was evident that Tow would be a complex session-type application. It also seemed that the authoring tools mentioned above, and some others we encountered, would not be suitable; some were not yet available, anyway. We needed something that allowed us to express menus in a similar way to MDDL, and also to specify error-checking on large amounts of numeric input data. In addition, we wanted eventually to be able to switch between generating server-side code and Java applets to run on the browser. We therefore developed our own tool, Web-O-Matic.
We finish by citing this as yet another example of an authoring tool, and one others may find of use - we found that it was between five and ten times quicker to develop pages with it than with more conventional methods. Since we often needed to test out new designs rapidly, this was rather convenient. A detailed account can be found in (Paine 1996), earlier work is described in (Paine 1995), and the tool itself is now available free of charge, in Java and with its own Web server, from my home page <http://www.j-paine.org/>. One advantage over the tools mentioned above is that Web-O-Matic is based on sound mathematical foundations, making it safer to maintain and extend.
C. Giles and J. McCrae (1995), "The IFS Microsimulation Tax and Benefit Model", IFS Working Paper W95/19.
J. Paine (1995), "Web-O-Matic: using System Limit Programming in a declarative object-oriented language for building complex interactive Web applications", Proceedings of the First Project David Workshop on Algebraic Document Processing and SGML, September 1996, Departamento de Informatica, Universidade do Minho. An on-line version is available.
J. Paine (1996), "Web-O-Matic/Rexx: A tool for writing interactive Web pages that works by compiling HTML into Object Rexx", Proceedings of 8th Rexx Symposium, Heidelberg 22-24 April 1997. An on-line version is available.
E. Raymond (1996), "The New Hacker's Dictionary", MIT Press 1996. An on-line version is available.
The author may be contacted at the following address:
Telephone +44 (0) 468 168398
Fax +44 (0) 1865 310447
e-mail popx@j-paine.org